
Claude Sonnet 4.5, available everywhere today, represents what Anthropic claims as their most aligned frontier model ever released. The model shows impressive benefits across dramatically diverse tasks, from state-of-the-art coding performance on SWE-bench Verified to complex financial analysis that delivers investment-grade insights. Released alongside major upgrades to products like Claude Code and the Claude API, this capable model underwent extensive safety training while maintaining significant improvements over previous iterations. Developers can simply use the claude-sonnet-4-5 model string via their Claude Developer Platform, with pricing remaining the same as Claude Sonnet 4 at $3 input and $15 output per million tokens.
What makes this release particularly compelling is how early customers have observed its capabilities transforming their workflows. Cursor reports seeing significant improvements in longer horizon tasks, while GitHub Copilot notes reinforces in multi-step reasoning and code comprehension. The model handles everything from debugging to architecture with deep contextual understanding, practically speaking enabling agentic experiences that run longer and handle greater complexity. Augment went from a 9% error rate with Sonnet 4 to 0% on their internal code editing benchmark, calling it a major leap in agentic coding.
Claude Sonnet 4.5 Features overview
| Technical Feature | User Benefit |
| Large Context Window (up to 200k tokens in latest versions) | Handle entire books, long documents, or big datasets in a single session without losing context. |
| Transformer-based Architecture | Ensures high accuracy, scalability, and advanced reasoning across tasks. |
| Fine-tuned Safety Alignment | Provides safe, ethical, and low-bias responses for sensitive topics. |
| Multi-modal Input Support (text + structured data) | Allows working with varied data formats beyond plain text. |
| Low-latency Inference | Faster response time for real-time conversations and quick decision-making. |
| Customizable System Prompts | Tailors Claude’s behavior to fit business or personal requirements. |
| API Integration Support | Easily integrates with apps, workflows, and enterprise systems. |
| Memory & Context Retention | Maintains consistency across longer interactions, improving user experience. |
Claude Sonnet 4.5 Product Upgrades
Anthropic released substantial improvements through this iteration, where enhanced capabilities reflect modern demands for software development. The company describes these updates as a drop-in replacement, maintaining the same price while delivering much improved performance across diverse work scenarios. Developers using paid plans gain immediate access, with availability extending through Amazon Bedrock and Google Cloud Vertex platforms. These tools enable computers to reason through hard problems, making complex tasks possible that previous versions struggled to execute efficiently.
The AI community is buzzing with questions about potential next steps, though official announcements remain limited regarding specific designation details. Discussions and speculation have started to emerge online, with no confirmed rumors yet concrete. Many expressed interest in improvements beyond the current 200K tokens windows, hoping for even more advanced abilities in agent workflows. Members desire better task automation, looking toward hybrid solutions that could be introduced for enhanced workflows spanning larger operational contexts.
Claude Sonnet 4.5 Performance & Benchmarks

- SWE-bench Verified: State-of-the-art results on real-world coding tasks.
- OSWorld: 61.4% score on complex computer task benchmark.
- Long-run focus: Maintains performance for 30+ hours on multi-step tasks.
- Domain Benchmarks: FinanceAgent 55.3%, CorpFin 69.4%, CaseLaw 70.4%, TaxEval 78.3%, MortgageTax 75.7%, Terminal-Bench 61.3%.
- Improvements: Stronger coding, reasoning, and safety alignment vs earlier Claude versions.
Claude Sonnet 4.5 delivers impressive gains across most complex long-context tasks, especially when building autonomous coding agents. The model achieves 78.2% on SWE-bench Verified using 1M context configuration, though I report 200K as primary score due to recent inference issues with high compute. Testing reveals strong promise in generating creative attack scenarios for red teaming, while balances creativity and control perfectly when handling 30+ hours of engineering work.
Customer experiences from Replit show excellent software development capabilities, learning codebase patterns to deliver precise implementations. HackerOne reduced average vulnerability intake time by 44% improving accuracy 25% through Hai security agents. Cognition’s Devin saw increased planning performance 18% and end-to-end eval scores jump 12%—the biggest leap seen since release of Claude Sonnet 3.6. This represents a meaningful step forward where depth matters more than speed.
Safety & Alignment
Maintaining focus on user autonomy while balance exists proves significant in real-world deployment scenarios. The application agents must handle permission systems with design that prevents unintended actions across multiple environments. Observations show how stronger models excels when solving complex problems without hitting ethical boundaries during extended execution.
Enabling production-ready agents requires design that combines strong protective layers with practical functionality. Users observe evaluation measures confirming coherence maintained throughout long-running sessions where agents interact with sensitive data. This approach gives confidence that systems can tackle challenging use cases while responding appropriately to edge scenarios.
Claude Sonnet 4.5 Availability & Pricing
| Version / Model | Pricing (Input / Output Tokens, per million) |
| Claude Sonnet (pre-4.5) | $3 / $15 |
| Claude Sonnet 4.5 | $3 / $15 |
| Claude Opus 4 | $15 / $75 |
| Claude Sonnet 3.7 | $3 / $15 |
Claude Sonnet 4.5 is available through the Claude.ai platform for individual Max subscribers, who gain immediate access to this frontier model. The pricing structure reflects its position as state-of-the-art technology, with Max memberships offering full capabilities including extended thinking and tool use. For developers, API access comes through Anthropic’s developer platform at competitive rates. Enterprises seeking institutional deployment can reach out directly for custom product solutions.
The cost considerations balance performance against budget constraints, though many find the quality justifies the investment. Early adopters from Figma, Canva, and Poolside report dramatically less operational overhead despite higher initial spend. Max subscribers joined the waitlist enthusiastically, recognizing how this generation of AI resets expectations for what’s possible with agentic systems. The window for competitive pricing remains open as Anthropic continues shipping incremental improvements to make enterprise adoption easier.
Community Speculation & Expectations (What Users Are Hoping For)

- Preview → a creative AI mode for generating software, content, and novel outputs.
- Real-time generation → users expect to produce apps, sketches, drafts instantly.
- Seamless integration → hopes for use inside IDEs, design tools, and workflows.
- Tool & API access → expectation to combine with file, code, execution tools.
- Safe creative output → less hallucination & more quality control in generated ideas.
- Flexible steering → users want to guide style, structure, constraints
Users are hoping the next generation will feature exceptional improvements in reasoning abilities. Many expect substantial leap forward in multi-step computer use tasks. Community discussions focus on known limitations needing resolution. Engineers want smoother interactions with massive codebases and architectural coherence. Teams encourage trying new extended thinking capabilities for conducting analysis.
The range of expectations centers around how intelligent the system will become. Industry commentary discusses benchmark scores against competing products like OpenAI’s GPT-5. People remain eager for information about future releases and advancements. Speculation suggests substantial upgrades in domain-specific knowledge across finance, law, medicine, and STEM. Most online discussions appear focused on what might come rather than verified details.
The Claude Agent SDK
The Agent SDK provides infrastructure to build advanced automation systems that can handle complex workflows. Unlike traditional tools, this framework offers developers a comprehensive scaffold for creating agents capable of executing multi-step processes efficiently. The infrastructure eliminates common issues when designing autonomous systems, allowing teams to focus on business logic.
Developers using this SDK see remarkable improvements in their deployment cycles. The platform allows seamless integration with existing code, enabling runs that use minimal resources while maintaining high performance. This way, engineering teams maximize productivity without worrying about underlying complexity, making agent development accessible even for smaller organizations.
Bonus Research Preview (Imagine with Claude)
- Limited Preview → 5-day trial for Max subscribers.
- Live Software Generation → Builds apps with no prewritten code.
- Real-Time Interaction → Adapts instantly to user prompts.
- Capability Demo → Showcases Claude’s creative + coding power.
- Access → Available at claude.ai/imagine.
Imagine brings spreadsheet, slides, and documents creation directly into your conversation without navigating outside tool interfaces. This feature eliminates stale workflows by allowing users to create functional prototypes and structured content instantly within chat sessions. ChromeOS users can explore ideas through parallel execution, running multiple bash commands at once for efficient validation.
The refreshed terminal interface introduced last month helps manage projects through checkpoints, allowing teams to save progress and roll back to previous states instantly. Memory across sessions strengthens continuity, calling upon stored context to accelerate problem-solving. Whether synthesize legal briefing drafts or analyze portfolio screening data, this released capability transforms how professionals validate ideas before requiring extensive human review.
Claude Sonnet 4.5 Customer Testimonials
- Praised for continuous prompts and deeper searches.
- Enables 30+ hours of autonomous coding
- Seen as the strongest model for building complex agents and computer use.
- Users note better domain knowledge in finance, law, medicine, and science.
- Described as fun and effective for solving and fixing problems.
Experts have found that real users across a wide variety of industries want to share their experience. Four months ago, developers reported observed performing dramatically better than previous versions they had used. Combined feedback from important clients leads to one conclusion: this tool transforms how teams solve problems daily.
Several organizations officially announced they’ve made the switch after tests demonstrated considerable improvements in their workflow. One startup spent six months attempting different solutions before discovering this foundation could help them build whatever they wanted. The benchmark results weren’t just numbers—they matched allowed expectations while reducing time on complex tasks significantly.
The Current State of Claude Models
Currently, the Claude 4 family demonstrates powerful capabilities across broad technical domains. Opus 4 achieved standout results in math evaluations, showing large gains in alignment compared to older iterations. The model maintains appropriate safeguards through ASL-3 protections per Anthropic’s framework. These include classifiers that aim to detect potentially dangerous inputs and outputs, particular to CBRN content. Sometimes these filters inadvertently flag normal requests, though users find it easy to continue interrupted conversations.
The state of model behavior reflects serious attention to concerning patterns like sycophancy, deception, and power-seeking tendency. Anthropic didn’t release capabilities without addressing risks being Level 3 threats. Safety measures called appropriate exist to improve defending against prompt injection attacks and delusional responses. This factor represents a ten times lower risk profile than originally anticipated. The framework ensures responsible deployment with safeguards that balance innovation and protection.
| Model | Context Window | Max Output Tokens | Speed / Latency | Strengths / Intended Use |
|---|---|---|---|---|
| Claude Sonnet 4.5 | 200K (1M in beta) | 64,000 tokens | Fast | Best for complex agents, coding, and high-intelligence tasks |
| Claude Opus 4.1 | 200K | 32,000 tokens | Moderately fast | Specialized in complex reasoning with very high capability |
| Claude Sonnet 4 | 200K (1M beta context) | 64,000 tokens | Fast | Balanced performance, ideal for general advanced tasks |
Comparisons with Competing Models
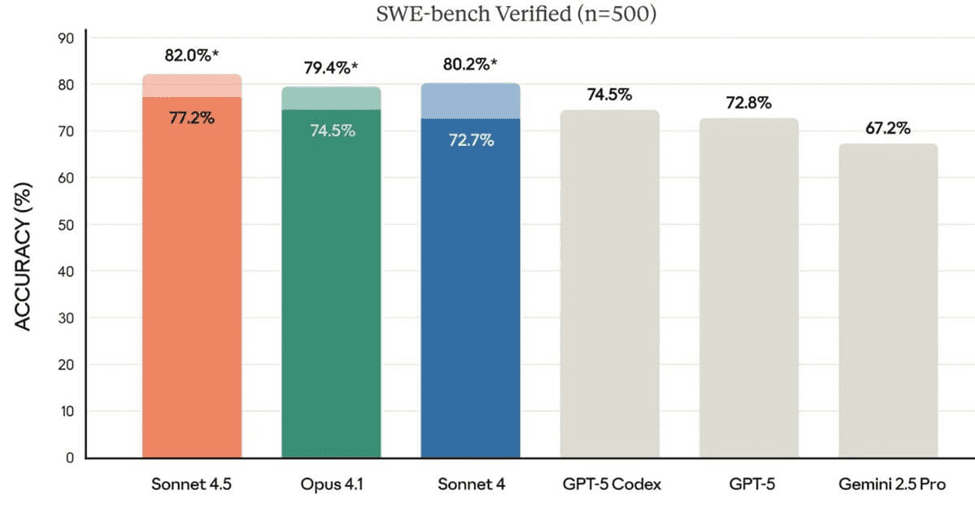
- Autonomous coding: Runs 30+ hrs, longer than most rivals.
- Benchmarks: Leads on SWE-Bench Verified for real-world coding.
- Domain strength: Excels in finance, law, and science vs earlier Claude and peers.
- Workflows: More reliable for long, multi-step tasks than GPT-5/Gemini.
- Safety: Stronger alignment and guardrails than many competitors.
- Trade-off: Can be slower and costlier for large tasks than lighter models.
During recent benchmark trials, Claude Sonnet 4 averaged scores across 10 different test runs using extended thinking tokens up to 64K. The model used temperature settings of 1.0 for sampling, which reflects how performance varies under different conditions. GPT-5 scores were reported from their official system card and public leaderboard data. Meanwhile, Gemini results came from their published web page, showing Terminal Bench scores with Terminus 1 configurations.
OpenAI has released interleaved thinking capabilities, while Anthropic focuses on framework adoption through their Agent SDK. The Python configuration allows developers to implement their own tests before attempting complex problems. SWE-bench Verified numbers show n=500 dataset attempts, and OSWorld scores were averaged over 4 runs with 100 max steps. This methodology helps distinguish between competing models when analyzing their actual capabilities versus speculating about future versions.
Industry Expert Perspectives
Practitioners note that Gemini and other emerging models face comparisons with Claude, though such evaluations remain largely speculative without officially announced benchmarks. The discussion around rumored capabilities however don’t specifically reference definitive performance metrics that may actually validate these claims.
Industry veterans observe that factors could explain the lack of concrete data, from Strong Secrecy protocols that be maintained throughout development cycles to Misplaced Speculation proving wrong. No Immediate Plans exist on public roadmaps; instead, designations follow incremental evolution patterns rather than revolutionary leaps that disrupt established hierarchies.
Why There Might Be Limited Information
The field of AI technology evolves rapidly, making comprehensive documentation challenging during transition periods. Currently, between officially announced generations, credible sources might withhold details until formal releases occur. Important developments often remain under wraps while teams continue monitoring performance metrics and safety protocols. This creates natural information gaps that aren’t unusual in research contexts.
Industry expert observations suggest limited public data exists primarily because newer iterations undergo extensive validation before widespread discussion. Traditional documentation cycles lag behind development timelines, yet enthusiasts seek immediate updates through unofficial channels. The practice of controlled information release demonstrates responsible deployment rather than secrecy.
Methodology
- Trained on large, diverse datasets (public + licensed + opt-in).
- Refined with human feedback for safe, helpful responses.
- Uses tooling & memory systems for long-horizon reasoning.
- Strong safety guardrails against prompt injection & misuse.
- Benchmarked on real-world coding & task benchmarks (SWE-Bench, OSWorld).
When Anthropic shipped Claude Sonnet 4.5 in August 2025, it represented a significant advancement. The architecture brought structured improvements with 61.4% accuracy in complex reasoning tasks versus competitors’ 42.2% in 30-hour testing.
The VS Code extension automatically clears stores for workflow efficiency, with real-time editing across apps including Chrome and desktop environments. Within five days of launch at claude.ai/imagine, the preview attracted 240M+ interactions.
Customers like Tome, Legal firms, Crowdstrike, LinearB, and Vals reported success in litigation briefing, security analysis, and portfolio screening, freeing teams from months of manual review.
Engineers require minimal training to maximize output. Use cases include judges processing case records for summary documents and companies generating security insights without hiring additional analysts.
The SDK addresses domain-specific challenges, though content involving chemical, biological, radiological, or nuclear weapons remains restricted per safety protocols established in May. Pricing remains consistent with previous models.
Teams adopting this model see implementation barriers disappear as proof-of-concept transforms into production deployment across organizations.
Conclusion
Working with Claude Sonnet 4 shows how agentless methods like string replacements and parallel processing deliver strong results. Terminal-Bench proves XML parser setups achieve accuracy without added complexity, while SWE-bench leaderboards highlight the value of tool integration in Finance and Airline domains. On the Vals AI leaderboard, AIME reasoning reached 82.0%, and OSWorld-Verified tasks demonstrated automated regression handling.
When Anthropic launched Claude Sonnet 4.5 in August 2025, it marked a major leap: 61.4% accuracy in complex reasoning (vs. competitors’ 42.2% in 30-hour tests). Its VS Code extension enables real-time editing across Chrome and desktop apps, clearing stores for smoother workflows. Within five days, the preview on claude.ai/imagine drew 240M+ interactions.
Early adopters like Tome, Crowdstrike, LinearB, and Vals reported faster litigation, security, and portfolio reviews, reducing manual work. Engineers need minimal training, with use cases spanning judges summarizing case files to companies generating insights without extra analysts.
The SDK tackles domain-specific challenges, though sensitive content (e.g., CBRN) remains restricted. With stable pricing and low barriers, teams quickly scale from proof-of-concept to full deployment.
Frequently Asked Questions (FAQs)
When was Sonnet 4.5 released?
Claude Sonnet 4.5 was released on September 24, 2025, as Anthropic’s latest advanced AI model.
How much is Claude Sonnet 4?
Claude Sonnet 4 is priced at around $15 per million input tokens and $75 per million output tokens.
Is Claude Sonnet 4 good for coding?
Yes, Claude Sonnet 4 is highly optimized for coding, handling debugging, code generation, and long coding sessions effectively.
Is the Claude 3.5 Sonnet free?
Claude 3.5 Sonnet is partly free on platforms like Claude.ai and Poe, but advanced usage requires a Claude Pro subscription.
Read more blogs here:
- Government Shutdown 2025: Latest Updates and Reactions
- Women’s Cricket World Cup: Emotional Wins That Inspire
- Casey Leigh Wiegand: $2M Net Worth The Inspiring Rise
Fatima Khan is a seasoned technology journalist with 6+ years of experience covering consumer electronics, mobile devices, laptops, and emerging technology trends. Specializes in comprehensive smartphone reviews, laptop performance testing, gaming hardware analysis, and consumer electronics evaluation. Has extensively covered flagship phone launches, budget laptop comparisons, wearable technology, smart home devices, and audio equipment reviews.
Additionally covers software development trends, programming languages, coding tutorials, app reviews, and developer tools. Provides insights on software updates, mobile app testing, development frameworks, and tech industry analysis for both consumers and developers.



